Multi-View Graph Convolutional Networks with Attention Mechanism
Kaixuan Yao Jiye Liang Jianqing Liang Ming Li Feilong Cao
Abstract
Recent advances in graph convolutional networks (GCNs), mainly focusing on how to exploit the information from different hops of neighbors in an efficient way, have brought substantial improvement on many graph data modelling tasks. Most of the existing GCN-based models however are built on the basis of a fixed adjacency matrix, i.e., a single view topology of the underlying graph. That inherently limits the expressive power of the developed models when the given adjacency matrix that is viewed as an approximation of the unknown graph topology does not fully reflect the `ideal’ structure knowledge. In this paper, we propose a novel framework, termed Multiview Graph Convolutional Networks with Attention Mechanism (MAGCN), by incorporating multiple views of topology and attention based feature aggregation strategy into the computation of graph convolution. Furthermore, we present some theoretical analysis about the expressive power and flexibility of MAGCN, which provides a general explanation on why multi-view based methods can potentially outperform the ones relying on a single view. Our experimental study demonstrates the state-of-the-art accuracies of MAGCN on Cora, Citeseer, and Pubmed datasets. Robustness analysis is also given to show the advantage of MAGCN in handling some uncertainty issues in node classification tasks.
Motivation
Despite that GCN and its variants/extensions have shown their great success on node classification tasks, almost all of these models are developed based on a fixed adjacency matrix given in advance, in other words, a single view graph topology. Inherently, the expressive power of the resulted model may be limited due to the potential information discrepancy between the adjacency matrix and the (unknown) target one. As such, it is logical to consider two practical questions:
Q1: Is the given topology (adjacency matrix) trustable?
Q2: How to carry out the neighborhood aggregation or message passing when multi-view topologies of the graph are provided?
In this paper, we propose a novel framework, termed Multiview Graph Convolutional Networks with Attention Mechanism (MAGCN), by incorporating multiple views of topology and attention based feature aggregation strategy into the computation of graph convolution.
Overview
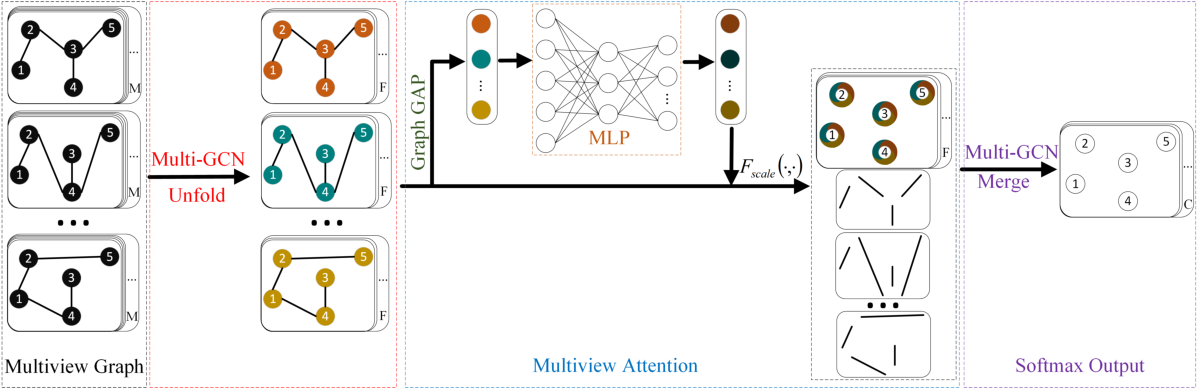
Figure 1. The overall structure of our MAGCN.
To better understand the proposed model, we provide a summary of the algorithm flow:
-
Multi-GCN (unfold): The multi-view graph
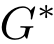 with 5 nodes, n topologies and a feature matrix
with 5 nodes, n topologies and a feature matrix 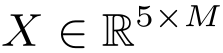 , is first expressed by the multi-GCN (unfold) block to obtain a multiview representation
, is first expressed by the multi-GCN (unfold) block to obtain a multiview representation 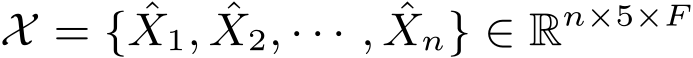 .
. -
Multiview Attention: Then a multiview attention is utilized to fuse the
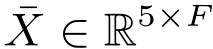 to a complete representation
to a complete representation 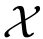 .
. -
Multi-GCN (merge): Finally, a multi-GCN (merge) block with softmax is introduced to obtain the final classification expressing matrix
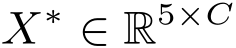 .
.
Experiments
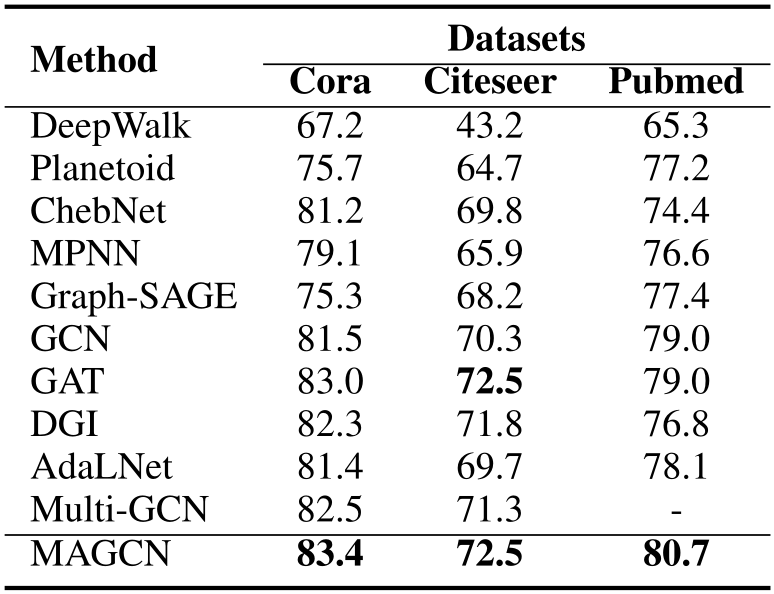
Semi-Supervised Classification.
Table 1. Semi-supervised Classification Accuracy (%).
Robustness Analysis.
To further demonstrate the advantage of our proposed method, we test the performance of MAGCN, GCN and GAT when dealing with some uncertainty issues in the node classification tasks. Here we only use Cora dataset, and consider two types of uncertainty issues: random topology attack (RTA) and low label rates (LLR), that can lead to potential perturbations and affect the classification performance.
Random Topology Attack (RTA)
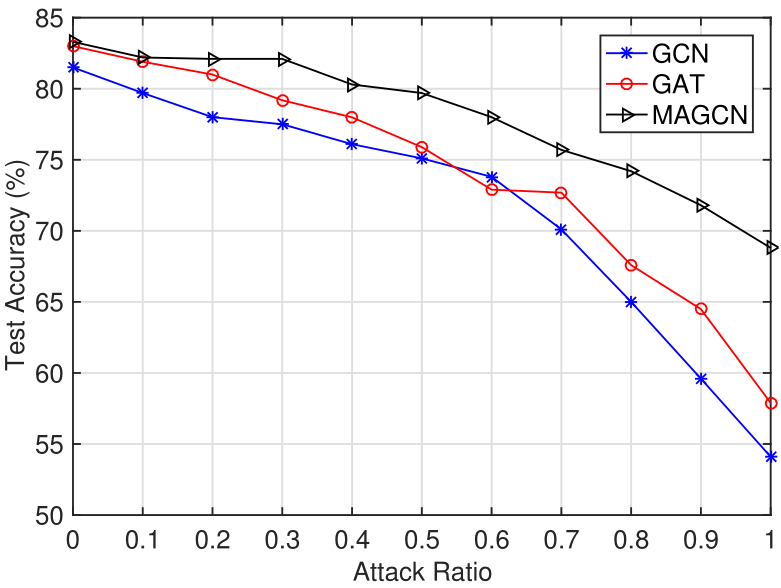
Figure 2. Test performance comparison for GCN, GAT, and MAGCN on Cora with different levels of random topology attack.
Low Label Rates (LLR)
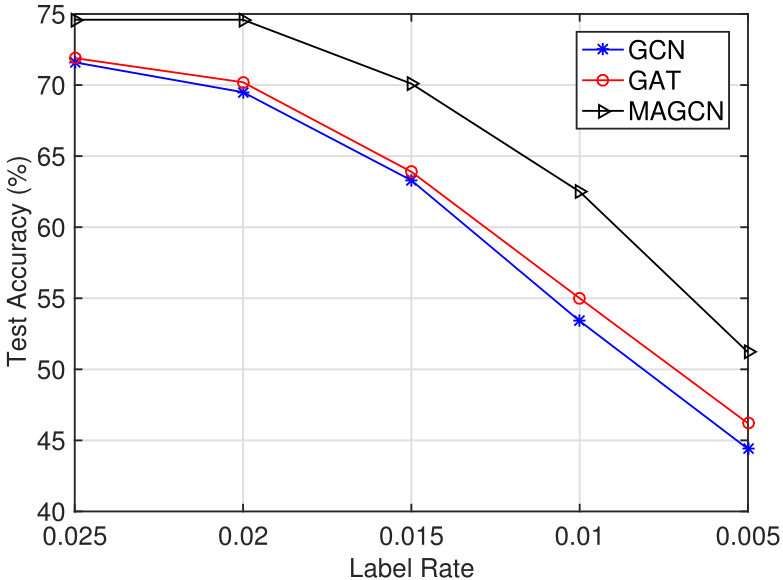
Figure 3. Test performance comparison for GCN, GAT, and MAGCN on Cora with different low label rates.
Visualization and Complexity
Visualization
To illustrate the effectiveness of the representations of different methods, a recognized visualization tool t-SNE is utilized. Compared with GCN, the distribution of the nodes representations in a same cluster is more concentrated. Meanwhile, different clusters are more separated.

Figure 4. t-SNE visualization for the computed feature representations of a pre-trained model's first hidden layer on the Cora dataset: GCN (left) and our MAGCN (right). Node colors denote classes.
Complexity
- GCN (Kipf & Welling, 2017):
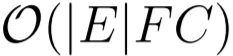
- GAT (Veličković et al., 2018):
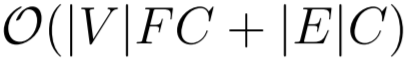
- MAGCN:
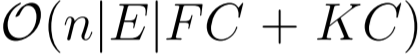
where ![]() and
and ![]() are the number of nodes and edges in the graph, respectively. F and C denote the dimensions of the input feature and output feature of a single layer. n denotes the number of the views,
are the number of nodes and edges in the graph, respectively. F and C denote the dimensions of the input feature and output feature of a single layer. n denotes the number of the views, ![]() is the cost of computing multi-view attention and K denotes the neuron number of multilayer perceptron (MLP) in multi-view attention block. Although the introduction of multiple views multiplies the storage and parameter requirements by a factor of n compared with GCN, while the individual views’ computations are fully independent and can be parallelized. Overall, the computational complexity is on par with the baseline methods GCN and GAT.
is the cost of computing multi-view attention and K denotes the neuron number of multilayer perceptron (MLP) in multi-view attention block. Although the introduction of multiple views multiplies the storage and parameter requirements by a factor of n compared with GCN, while the individual views’ computations are fully independent and can be parallelized. Overall, the computational complexity is on par with the baseline methods GCN and GAT.
Applications
In the real-world graph-structured data, nodes have various roles or characteristics, and they have different types of correlations. Multiview graph learning/representation is of great importance in various domains. Here, we will provide a gentle introduction of possible applications of our proposed MAGCN (or its potential variants in both architecture/algorithm level).
Conclusion
We propose in this paper a novel graph convolutional network model called MAGCN, allowing us to aggregate node features from different hops of neighbors using multi-view topology of the graph and attention mechanism. Theoretical analysis on the expressive power and flexibility is provided with rigorous mathematical proofs, showing a good potential of MAGCN over vanilla GCN model in producing a better node-level learning representation. Experimental results demonstrate that it yields results superior to the state of the art on the node classification task. Our work paves a way towards exploiting different adjacency matrices representing distinguished graph structure to build graph convolution.
Citation
If you make advantage of the MAGCN model in your research, please cite the following in your manuscript:
@article{
yaokx2022MAGCN,
title="{Multi-View Graph Convolutional Networks with Attention Mechanism}",
author={Yao, Kaixuan and Liang, Jiye and Liang, Jianqing and Li, Ming and Cao, Feilong},
journal={Artificial Intelligience},
year={2022},
pages={103708},
url={https://doi.org/10.1016/j.artint.2022.103708},
}